Haberler
Sesame AI etkileyici sesli asistanını tanıttı
Kaliforniya merkezli start-up Sesame AI, daha gerçekçi diyaloglar oluşturmak için mikro duraklamalar, tonlama ve kahkaha gibi kasıtlı kusurları kullanan bir konuşma modeli geliştirdi.
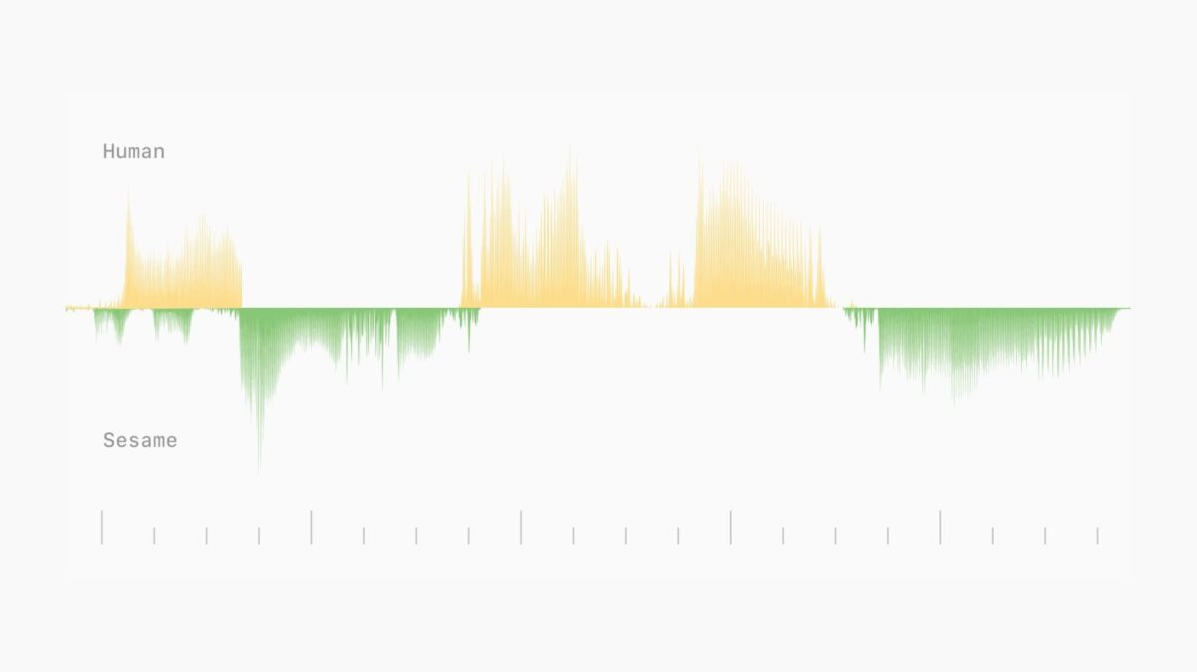
Kaliforniya merkezli bir startup olan Sesame AI, konuşma çıktısına kasıtlı olarak kusurları dahil ederek sesli yapay zekaya alışılmadık bir yaklaşım getiriyor. Yeni modelleri, daha otantik diyaloglara ve yapay zeka sistemlerinde “ses varlığı” olarak adlandırdıkları şeye doğru erken bir adımı temsil ediyor.
İlk testlere göre, Sesame’ın en etkileyici özellikleri, konuşmalar sırasında mikro duraklamalar, vurgu değişimleri ve kahkahalar gibi ince unsurlar. Bir etkileşimde, Sesame’in avatarı Maya, bir kullanıcının ani kıkırdamasına gerçek zamanlı olarak yanıt vererek duygusal farkındalık gösterdi.
Sistem, cümle ortasında kendi kendini düzeltme, kesintiler için özür dileme ve dolgu sözcükleri gibi insan benzeri davranışları kasıtlı olarak içeriyor. Techradar bu kasıtlı kusurları özellikle övdü ve ChatGPT veya Gemini’nin cilalı kurumsal tonundan ne kadar farklı olduklarına dikkat çekti.
İş stresi veya parti planlaması hakkındaki tartışmalar gibi simüle edilmiş senaryolarda, sistem genel ifadelere geri dönmek yerine bağlama uygun yanıtlar ve sorular sağladı.
Sesame AI semantik ve akustik belirteçleri kullanıyor
Henüz resmi bir makale yayınlanmamış olsa da, Sesame’in blog yazısı mimarileri hakkında fikir veriyor. CSM, temel işleme için bir omurga transformatörünü (1-8 milyar parametre) ses üretimi için daha küçük bir kod çözücü (100-300 milyon parametre) ile birleştiren iki parçalı bir transformatör yapısı kullanıyor.
Sistem, perde ve vurgu gibi ses özellikleri için akustik belirteçlerin yanı sıra dilsel özellikler ve fonetik için semantik belirteçler kullanarak konuşmayı işliyor. Eğitimi optimize etmek için, ses kod çözücü ses karelerinin yalnızca on altıda biri üzerinde eğitilirken, anlamsal işleme tüm veri kümesini kullanıyor.
Model, beş dönem boyunca bir milyon saatlik İngilizce ses verisi üzerinde eğitildi. Uçtan uca bir mimaride 2.048 jetona kadar (yaklaşık iki dakikalık ses) dizileri işleyebiliyor. Bu yaklaşım, metin ve sesi entegre bir şekilde işlemesiyle geleneksel metinden sese sistemlerinden ayrılıyor.
Blog yazısında doğrudan belirtilmese de demo ses, Google’ın açık kaynaklı LLM Gemma’sının 27 milyar parametreli bir versiyonunu kullandığını ortaya koyuyor.
Testler insana yakın performans ortaya koyuyor
Sesame ile yapılan kör testlerde, katılımcılar kısa konuşma parçacıkları sırasında CSM ile gerçek insanlar arasında ayrım yapamadı. Bununla birlikte, daha uzun diyaloglar, zaman zaman doğal olmayan duraklamalar ve ses artefaktları gibi sınırlamaları ortaya çıkardı.
Sesame, model performansını ölçmek için özel fonetik kıyaslamalar geliştirdi. Dinleme testlerinde, katılımcılar üretilen konuşmayı bağlam olmadan duyduklarında gerçek kayıtlara eşdeğer olarak değerlendirdiler, ancak bağlam sağlandığında orijinali tercih etmeye devam ettiler.
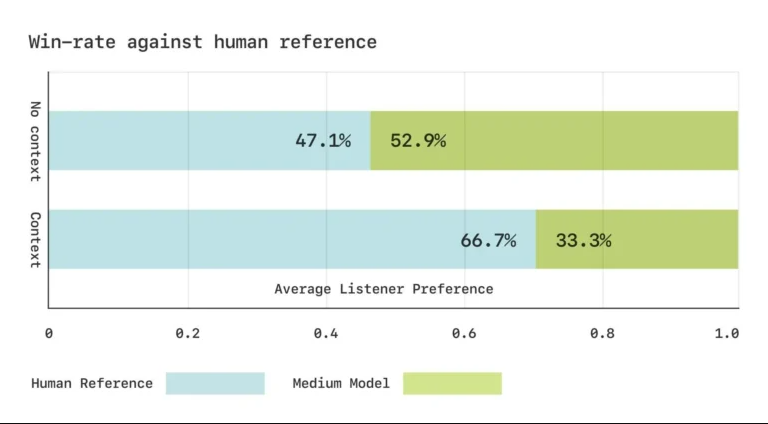
Deneklerin yapay zeka tarafından üretilen konuşma tercihi neredeyse insani seviyelere ulaşıyor. | Resim: Sesame AI
Gelecekteki gelişmeler ve açık kaynak planları
Sesame, araştırmalarının temel bileşenlerini Apache 2.0 lisansı altında açık kaynak olarak yayınlamayı planlıyor. Önümüzdeki aylarda, hem model boyutunu hem de eğitim kapsamını büyütmeyi ve 20’den fazla dile genişletmeyi planlıyorlar.
Şirket özellikle önceden eğitilmiş dil modellerini entegre etmeye ve konuşmacı geçişleri, duraklamalar ve hızlanma gibi konuşma dinamiklerini doğrudan verilerden öğrenebilen tam çift yönlü yetenekli sistemler geliştirmeye odaklanıyor. Bu gelişme, veri küratörlüğünden eğitim sonrası yöntemlere kadar işleme hattı boyunca temel değişiklikler gerektirecek.
Geliştiriciler, “Sesli varlığa sahip dijital bir yol arkadaşı oluşturmak kolay değil, ancak kişilik, hafıza, ifade ve uygunluk dahil olmak üzere birçok cephede istikrarlı bir ilerleme kaydediyoruz” diyor.
Eski Oculus CTO’su Brendan Iribe ve ekibi tarafından kurulan Sesame AI, Andreessen Horowitz liderliğinde önemli bir A Serisi fon sağladı. Bir demo mevcut.
Doğal yapay zeka seslerinin asistanların benimsenmesi üzerindeki etkisi, ChatGPT’nin Gelişmiş Ses Modu etrafındaki heyecanla kanıtlandı. LLM’ler tarafından desteklenen sesli asistanların, Amazon’un Alexa+’ı piyasaya sürmesinin de gösterdiği gibi, giderek daha yaygın hale gelmesi muhtemel.
Kaynak: The Decoder
Haberler
Danimarka, insanların kendi özelliklerini telif hakkıyla korumayı planlıyor
Danimarka hükümeti, vatandaşlarına kendi bedenleri, yüz özellikleri ve sesleri üzerinde hak sahibi olmalarını sağlamak için telif hakkı yasasını değiştirmeye hazırlanıyor. Bu dönüm noktası niteliğindeki yasa, deepfake’lerin oluşturulması ve yayılmasına karşı korumayı güçlendirmek için tasarlandı.

Haberler
Meta, ses klonlama girişimi Play AI’ı satın almaya hazırlanıyor
Meta, yapay zeka araştırma yetenek havuzunu güçlendirmenin yanı sıra, tüketiciye yönelik yapay zeka özelliklerini de geliştirmeye istekli görünüyor. Şirket, Play AI adlı bir ses klonlama girişimini satın almak için görüşmeler yürütüyor.

Haberler
ElevenLabs, yapay zeka özelliklerine sahip mobil uygulamasını başlattı
Sesli yapay zeka şirketi ElevenLabs, iOS ve Android için kullanıcıların hareket halindeyken metinden ses klipleri oluşturmasına olanak tanıyan, etiketler aracılığıyla ifade kontrolü ve popüler içerik oluşturma uygulamalarıyla sorunsuz entegrasyon sağlayan en yeni v3 alfa metinden sese modellerine erişim sunan bağımsız bir mobil uygulama başlattı.


Danimarka, insanların kendi özelliklerini telif hakkıyla korumayı planlıyor

Meta, ses klonlama girişimi Play AI’ı satın almaya hazırlanıyor
ElevenLabs, yapay zeka özelliklerine sahip mobil uygulamasını başlattı







 Haberler3 yıl önce
Haberler3 yıl öncePodcast’ten para kazanmanın 12 yolu
- Haberler3 yıl önce
Spotify’dan ‘Şişedeki Çalma Listesi’
- Etkinlik2 yıl önce
‘Podcast Dinliyorum’ etkinliğinin ikincisi 25 Ekim’de
- Araştırma11 ay önce
Popüler podcast yayıncıları sektördeki en büyük zorlukları yorumluyor
- Araştırma3 yıl önce
Mart ayına Anchor, Buzzsprout ve Spreaker damgası
- Haberler3 yıl önce
Video podcast nedir?
- Haberler3 yıl önce
Podcast’leri nasıl daha hızlı dinleyebilirsiniz?
- Haberler3 yıl önce
Daniel Ek Spotify’ın büyük vizyonunu anlattı